

A100이 V100보다 빠르다는 건 다들 알고 있습니다. 그런데 얼마나, 어디서 차이가 나는 걸까요?
두 세대 모두 NVLink를 지원하고, PyTorch DDP를 실행할 수 있고, 학술 HPC(고성능 컴퓨팅, High-Performance Computing) 클러스터에 설치되어 있습니다. 그런데 막상 수치를 뽑아서 비교하려고 하면 생각보다 까다로운 문제들이 생깁니다. VRAM 용량 차이 때문에 배치 사이즈를 다르게 설정해야 하고, CUDA 빌드 제약 때문에 설치할 수 있는 PyTorch 버전도 달라집니다. 또 “최대 처리량"을 보느냐 “멀티 GPU 스케일링 효율"을 보느냐에 따라 비교 결과가 달라지기도 합니다.
이 포스트에서는 동일한 벤치마크 코드를 8xV100 SXM2 16GB와 8xA100 SXM4 80GB에서 실행한 결과를 다룹니다. GPU와 인터커넥트를 다르게 스트레스 테스트하는 두 가지 모델, ResNet-152(컴퓨트 집약적 CNN)와 ViT-B/16(통신 집약적 트랜스포머)를 사용했습니다. 벤치마크 툴은 오픈소스이고, 자세한 설명은 포트폴리오 페이지에서 확인하실 수 있습니다. 코드와 결과는 모두 GitHub 저장소에 있습니다.
1. 단순 비교가 어려운 이유 #
같은 배치 사이즈로 두 GPU를 돌려서 처리량을 비교하면 될 것 같지만, 실제로는 바로 문제가 생깁니다. V100은 16GB, A100은 80GB이기 때문입니다. V100에서 가능한 최대 배치 사이즈는 A100이 사용할 수 있는 것보다 훨씬 작습니다. A100을 V100 기준 배치 사이즈로 돌리면 성능이 인위적으로 낮게 나오고, V100을 A100 기준으로 돌리면 OOM(Out Of Memory)이 발생합니다.
그래서 이 벤치마크에서는 비교를 두 부분으로 나눴습니다.
약 스케일링(Weak Scaling) 효율은 GPU당 배치 사이즈를 고정한 채 1개에서 8개로 늘렸을 때 각 시스템이 얼마나 잘 스케일링되는지를 측정합니다. 이 지표는 정규화된 비율입니다. 1-GPU 처리량 대비 N-GPU에서 얼마를 유지하는지를 퍼센트로 나타냅니다. 8-GPU에서 95%라는 건 5%가 DDP 통신 오버헤드로 손실됐다는 의미입니다. 두 시스템이 다른 배치 사이즈를 사용하더라도 이 비교는 유효합니다.
절대 처리량은 각 시스템의 최대 안전 배치 사이즈에서 GPU당 초당 이미지 수를 비교합니다. “각 GPU 최상의 상태"를 비교하는 것입니다. 배치 사이즈 차이가 변수로 남아 있으니, 통제된 실험이라기보다 “각자 최선을 다했을 때"의 비교로 봐야 합니다.
강 스케일링(Strong Scaling)은 배치 사이즈 차이에 가장 민감합니다. GPU가 늘어날수록 GPU당 배치가 줄어들기 때문에, VRAM이 작은 GPU는 금방 한계에 부딪힙니다. V100의 경우 GBS=64에서 8-GPU 실행 시 GPU당 8장만 처리합니다. 이는 완전히 통신 병목 구간입니다. A100은 GBS=512를 사용해서 8-GPU에서도 GPU당 64장이 들어갑니다. 직접 비교가 유효하지 않기 때문에, 강 스케일링 결과는 각 시스템별로 따로 제시합니다.
2. 실험 환경 #
하드웨어:
- 8xNVIDIA V100 SXM2 16GB (NVLink 2.0), Lambda Cloud
- 8xNVIDIA A100 SXM4 80GB (NVLink 3.0), Lambda Cloud
소프트웨어:
- V100: PyTorch 2.4.1, CUDA 12.6, Python 3.10
- A100: PyTorch 2.12.0, CUDA 13.0, Python 3.12
PyTorch 버전 차이에 대해: 최근 PyTorch 빌드(cu130)는 V100의 컴퓨트 캐퍼빌리티인 sm_70을 더 이상 포함하지 않습니다. V100에서는 구버전 wheel을 사용해야 하기 때문에, 처리량 차이에 PyTorch 버전 차이가 일부 포함됩니다. 약 스케일링 효율 비교는 각 시스템 내부에서 정규화되기 때문에 이 영향이 훨씬 적습니다.
모든 실행에서 GPU 위에서 직접 생성한 합성 데이터, torchrun DDP, SGD 옵티마이저를 사용했습니다. 각 작업은 60초 워밍업 후 300~600초 측정입니다. 최대 안전 배치 사이즈는 find_max_bs.py로 확인했습니다:
| GPU | ResNet-152 fp16 | ViT-B/16 fp16 |
|---|---|---|
| V100 SXM2 16GB | 128 | 128 |
| A100 SXM4 80GB | 512 | 1024 |
3. 약 스케일링 결과 #
약 스케일링은 GPU당 배치 사이즈를 고정합니다. GPU 수가 늘어도 GPU당 처리량이 일정해야 이상적입니다. 떨어지는 만큼이 NCCL gradient allreduce 통신 오버헤드입니다.
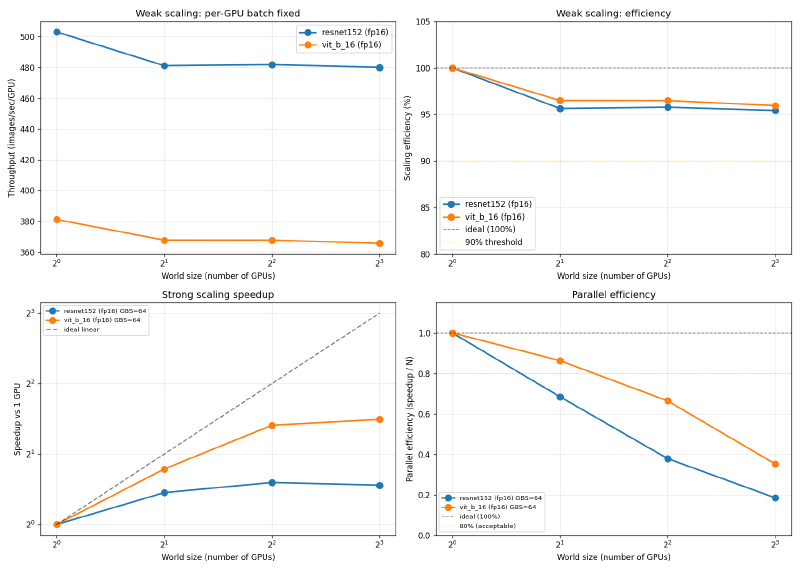
V100 SXM2 16GB, fp16, GPU당 BS=128:
| 모델 | 1-GPU | 2-GPU 효율 | 4-GPU 효율 | 8-GPU 효율 |
|---|---|---|---|---|
| ResNet-152 | 503 img/s | 95.6% | 95.8% | 95.4% |
| ViT-B/16 | 381 img/s | 96.5% | 96.5% | 95.9% |
A100 SXM4 80GB, fp16:
| 모델 | GPU당 BS | 1-GPU | 2-GPU 효율 | 4-GPU 효율 | 8-GPU 효율 |
|---|---|---|---|---|---|
| ResNet-152 | 512 | 1190 img/s | 98.9% | 98.1% | 97.4% |
| ViT-B/16 | 1024 | 1030 img/s | 98.9% | 98.6% | 98.0% |
A100 SXM4 80GB, bf16:
| 모델 | GPU당 BS | 1-GPU | 2-GPU 효율 | 4-GPU 효율 | 8-GPU 효율 |
|---|---|---|---|---|---|
| ResNet-152 | 512 | 1012 img/s | 99.3% | 98.9% | 98.5% |
| ViT-B/16 | 1024 | 1033 img/s | 99.6% | 99.3% | 98.9% |
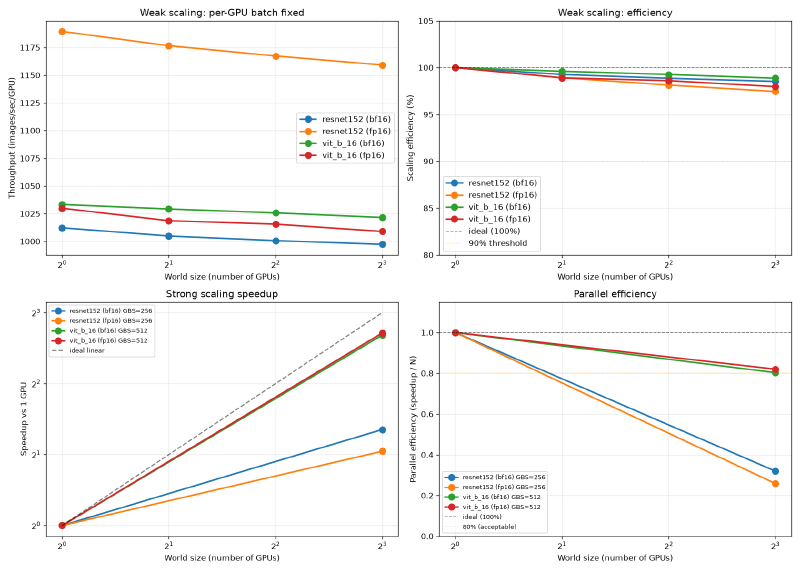
두 시스템 모두 잘 스케일링됩니다. V100은 8-GPU에서 95~96%, A100은 97~99%를 달성했습니다. 2~3%p 차이는 NVLink 3.0(양방향 600 GB/s) vs NVLink 2.0(양방향 300 GB/s)의 대역폭 차이를 반영합니다. 여기서 사용한 배치 사이즈 기준으로, V100은 A100보다 gradient 동기화 대기 시간이 조금 더 깁니다.
절대 처리량 비교 (fp16, 각 GPU 최대 배치 사이즈 기준):
| 모델 | V100 1-GPU | A100 1-GPU | 비율 |
|---|---|---|---|
| ResNet-152 | 503 img/s | 1190 img/s | 2.37배 |
| ViT-B/16 | 381 img/s | 1030 img/s | 2.70배 |
A100이 ResNet-152에서 약 2.4배, ViT-B/16에서 약 2.7배 더 빠르게 나왔습니다. ViT에서 격차가 더 큰 것은, A100의 개선된 Tensor Core 처리량과 더 높은 메모리 대역폭(2.0 TB/s vs V100 0.9 TB/s)이 GEMM(행렬 곱셈) 연산이 많은 워크로드에서 더 큰 효과를 내기 때문입니다.
4. A100에서 fp16 vs bf16 #
A100은 fp16과 bf16 모두 하드웨어로 지원합니다. 두 포맷은 값 하나에 2바이트를 사용해서 VRAM 사용량은 동일합니다. 성능 차이는 연산 경로에서 발생합니다.
| 모델 | fp16 | bf16 | 차이 |
|---|---|---|---|
| ResNet-152 | 1190 img/s | 1012 img/s | fp16이 17% 빠름 |
| ViT-B/16 | 1030 img/s | 1033 img/s | 사실상 동일 |
ResNet-152는 fp16이 17% 빠르고, ViT-B/16은 차이가 없습니다. 이유는 메모리 레이아웃에 있습니다. ResNet은 channels_last (NHWC) 포맷을 사용합니다. cuDNN의 conv 커널은 정밀도에 따라 이를 다르게 처리하는데, A100에서 fp16 NHWC 경로가 bf16보다 더 최적화되어 있습니다. ViT-B/16은 attention 연산이 convolution이 아니라 channels_last를 사용하지 않습니다. 그래서 precision 차이가 메모리 레이아웃과 상호작용하지 않습니다.
트랜스포머 학습 문서에서 “Ampere에서는 bf16을 사용하라"는 말을 자주 볼 수 있는데, 이 조언이 CNN 워크로드에는 그대로 적용되지 않습니다. ResNet 계열 모델이라면 A100에서도 fp16이 더 빠른 선택입니다.
5. 강 스케일링 결과 #
강 스케일링은 전체 배치 사이즈를 고정하고 GPU가 늘수록 얼마나 빨리 끝나는지를 측정합니다. 이상적인 speedup은 N개 GPU에서 N배입니다.
직접 비교는 유효하지 않습니다. V100과 A100이 서로 다른 GBS를 사용하는 이유는 V100의 VRAM이 1-GPU 기준 실행을 제약하기 때문입니다. 아래 표는 각 시스템을 독립적으로 보여줍니다.
V100 SXM2 16GB, fp16, GBS=64 (8-GPU에서 GPU당 8장):
| 모델 | 1-GPU | 8-GPU speedup | 8-GPU 효율 |
|---|---|---|---|
| ResNet-152 | 461 img/s | 1.47배 | 18.4% |
| ViT-B/16 | 367 img/s | 2.81배 | 35.1% |
A100 SXM4 80GB, fp16, GBS=512 (8-GPU에서 GPU당 64장):
| 모델 | 1-GPU | 8-GPU speedup | 8-GPU 효율 |
|---|---|---|---|
| ResNet-152 | 961 img/s | 2.55배 | 31.9% |
| ViT-B/16 | 1061 img/s | 6.42배 | 80.3% |
GPU당 배치 사이즈가 작아지면 강 스케일링 효율이 급격히 떨어집니다. V100 GBS=64에서 8-GPU를 사용하면 GPU당 8장만 처리합니다. 이 크기에서는 gradient allreduce가 순전파+역전파보다 오래 걸립니다. V100 ResNet-152의 8-GPU 효율이 18.4%인 것은, GPU 7개를 더 사용해도 1.47배 speedup밖에 안 된다는 의미입니다.
ViT-B/16이 더 나은 결과(V100 35.1%, A100 80.3%)를 보이는 이유는, ViT가 같은 배치 사이즈에서 ResNet보다 step당 연산이 더 많기 때문입니다. 연산과 통신이 더 많이 겹칠 수 있어서, 동기화 대기 시간의 비율이 낮아집니다.
6. 수치가 시스템 선택에 주는 의미 #
두 시스템 모두 약 스케일링에서는 잘 동작합니다 (8-GPU에서 95% 이상). 핵심 질문은 비용 차이가 처리량 차이를 정당화하느냐입니다.
A100은 GPU당 2.4~2.7배 더 많은 처리량을 냅니다. Lambda의 A100 시간당 비용이 V100의 2.4배 미만이라면, 학습 샘플당 비용은 A100이 유리합니다. 큰 전체 배치 사이즈가 필요하고 강 스케일링으로 학습을 빨리 끝내야 한다면, A100이 구조적으로 유리합니다. 더 큰 VRAM 덕분에 GPU 수가 늘어도 GPU당 배치 사이즈를 효율적으로 유지할 수 있기 때문입니다. V100은 금방 한계에 부딪힙니다.
GPU당 16GB에 워크로드가 들어가고 약 스케일링으로 많은 노드에 걸쳐서 실행하는 경우라면, 가격에 따라 V100의 95% 효율도 충분히 cost-effective할 수 있습니다.
7. 트러블슈팅 #
V100에서 CUDA error: no kernel image is available for execution on the device
최근 PyTorch wheel(cu130, cu128)은 V100의 sm_70을 포함하지 않습니다. cu126을 설치하세요:
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu126
python -c "import torch; print(torch.cuda.get_arch_list())"
# 출력에 sm_70이 포함되어 있는지 확인하세요1-GPU 강 스케일링 기준 실행에서 OOM
1-GPU 강 스케일링 실행은 GPU당 BS = GBS가 됩니다. GBS가 GPU의 안전 배치 사이즈를 넘으면 멀티 GPU 실행 전에 OOM이 발생합니다. find_max_bs.py로 상한을 확인하고 그 이하로 GBS를 설정하십시오:
python find_max_bs.py --model resnet152 --precision fp16analyze_results.py에서 step time 분산 경고
GPU 수가 많을 때 강 스케일링에서 GPU당 배치 사이즈가 아주 작아지면 당연히 나타나는 현상입니다. GPU가 통신 병목 상태에서 step 타이밍이 불규칙해집니다. 통신 오버헤드 분석 목적에서는 무시해도 됩니다. 큰 배치 사이즈를 사용하는 약 스케일링 결과에서 분산이 높게 나오면 그때 확인이 필요합니다.
8. 요약 #
이 벤치마크에서 얻은 세 가지 핵심 결과입니다.
V100과 A100 모두 약 스케일링에서 8-GPU 기준 95% 이상의 효율을 유지합니다. 두 시스템 사이의 2~3%p 격차는 NVLink 3.0 vs NVLink 2.0 대역폭 차이를 반영하는 것이지, 스케일링 방식 자체가 근본적으로 다른 것은 아닙니다.
A100은 ResNet-152에서 2.37배, ViT-B/16에서 2.70배 더 많은 처리량을 냅니다. 메모리 대역폭과 Tensor Core 처리량이 모두 기여하고, GEMM 집약적인 ViT에서 격차가 더 큽니다.
A100에서는 fp16이 bf16보다 ResNet-152 기준 17% 빠른 결과가 나왔습니다. cuDNN NHWC conv 커널 최적화 차이 때문입니다. ViT-B/16은 두 precision 간 차이가 없습니다. “Ampere에서는 bf16을 사용하라"는 조언이 CNN 워크로드에는 그대로 적용된다고 가정하면 안 됩니다.
모든 벤치마크 스크립트, raw JSON 결과, 플롯은 GitHub 저장소에 있습니다.
즐거운 컴퓨팅 되세요!